Populacja ogólna i metoda pobierania próbek. Populacje ogólne i próbne
Konieczność przeprowadzenia badań reprezentacyjnych może wynikać z różnych przyczyn:
często pełne badanie badanego zjawiska jest zbyt kosztowne i czasochłonne;
czasami możliwość wykorzystania informacji uzyskanych w pełnym opracowaniu może zostać wyczerpana przed zakończeniem procesu jego przygotowania;
w niektórych przypadkach w wyniku sprawdzenia jakości produktu badany obiekt ulega zniszczeniu.
Przykład:
Załóżmy, że populacją są wszyscy uczniowie szkoły (600 osób z 20 klas, po 30 osób w każdej klasie). Przedmiotem badań są postawy wobec palenia.
Populacja to zbiór obiektów, o których należy uzyskać informacje.
Populacja ogólna składa się ze wszystkich obiektów, które mają cechy i właściwości interesujące badacza. Czasami populacją ogólną jest cała dorosła populacja danego regionu (na przykład podczas badania stosunku potencjalnych wyborców do kandydata), najczęściej określa się kilka kryteriów określających przedmiot badań. Na przykład kobiety w wieku 10–89 lat, które przynajmniej raz w tygodniu używają kremu do rąk określonej marki i mają dochód co najmniej 5 tysięcy rubli na członka rodziny.
Próbka to mały zbiór obiektów wyodrębnionych z populacji.
Populacja próby to minimum wymagane do badania wyników (przypadków, podmiotów, obiektów, zdarzeń, próbek) wybranych przy użyciu określonej procedury z populacji ogólnej.
Przykłady:
identyfikacja reakcji klientów firmy na innowacje; wszyscy klienci firmy reprezentują ogół społeczeństwa; Ci klienci, do których zadzwoniono, stanowią próbkę.
Badając firmy posiadające dużą liczbę transakcji, należy poprzestać na badaniu wybranej liczby transakcji. Wszystkie transakcje przedsiębiorstwa stanowią populację ogólną, wybrane stanowią próbę.
ogólna populacja składa się ze wszystkich poborowych danego roku.
Wszystkie lampy wyprodukowane przez określony czas w określonym przedsiębiorstwie tworzą populację ogólną. Wybierane są te lampy, które zostaną wybrane do sterowania.
Próbkę można uznać za reprezentatywną lub niereprezentatywną. Próba będzie reprezentatywna przy badaniu dużej grupy osób, jeśli w tej grupie znajdują się przedstawiciele różnych podgrup, tylko w ten sposób można wyciągnąć prawidłowe wnioski. .
Reprezentatywność to zgodność cech próby z cechami populacji lub populacji ogólnej jako całości. Reprezentatywność określa, w jakim stopniu możliwe jest uogólnienie wyników badania na określonej próbie na całą populację, z której została ona zebrana.
Reprezentatywność można również zdefiniować jako właściwość populacji próbnej polegającą na reprezentowaniu parametrów populacji ogólnej, które są istotne z punktu widzenia celów badania.
Przykład: Próba 60 uczniów szkół średnich reprezentuje populację znacznie słabiej niż próba tych samych 60 osób, obejmująca po 3 uczniów z każdej klasy. Główną przyczyną jest nierówny rozkład wieku w klasach. W rezultacie w pierwszym przypadku reprezentatywność próby jest niska, a w drugim przypadku wysoka (przy wszystkich innych czynnikach niezmienionych) .
Zadanie 1. W mieście liczącym 253 000 uprawnionych do głosowania zbadaj skłonności polityczne przyszłych wyborców.
Rozwiązanie
Próbę można zbudować, przeprowadzając wywiady z co 15. kupującym opuszczającym duże centrum handlowe. Próba taka będzie odzwierciedlała poglądy osób odwiedzających centrum handlowe, ale jest mało prawdopodobne, aby reprezentowała poglądy wszystkich mieszkańców miasta.
Inną metodą konstruowania próby jest przeprowadzenie badania telefonicznego co 100. mieszkańca miasta, pobierając numery z książki telefonicznej. To systematyczne pobieranie próbek dostarczy informacji o poglądach grupy osób, które mają telefon, są w domu i odbierają telefon. Nie odzwierciedla to jednak opinii wszystkich mieszkańców miasta.
Inną metodą skonstruowania próby byłoby przeprowadzenie wywiadów z uczestnikami wiecu organizowanego przez kilka partii politycznych. Próba taka dostarczy informacji o mieszkańcach aktywnie uczestniczących w życiu politycznym miasta.
Potrzebujemy więc metod tworzenia próby, która reprezentowałaby całą populację, czyli próba musi być reprezentatywna (reprezentatywna).
Zadanie 2. Określ, czy próbka jest reprezentatywna:
1) liczbę wypadków samochodowych w czerwcu, jeżeli konieczne jest sporządzenie raportu statystycznego o wypadkach w mieście za dany rok;
2) mieszkańcy miast przy obliczaniu liczby samochodów na mieszkańca w kraju;
3) osoby w wieku od 40 do 50 lat przy ustalaniu oglądalności młodzieżowego programu telewizyjnego.
Rozwiązanie
1) Próbka nie jest reprezentatywna. Latem na drogach nie ma śniegu ani lodu, co jest jedną z głównych przyczyn wypadków.
2) Próba nie jest reprezentatywna. Wiadomo, że w mieście jest znacznie więcej samochodów niż na wsi. Należy to wziąć pod uwagę.
3) Próba nie jest reprezentatywna. Jest mało prawdopodobne, aby osoby w wieku od 40 do 50 lat wykazywały zainteresowanie programem skierowanym do młodych odbiorców. Przy zastosowaniu takiej próbki ocena może znacznie spaść, ale nie będzie to odzwierciedlać rzeczywistego stanu rzeczy. Aby utworzyć populację próbną, stosuje się różne metody selekcji. Statystyki muszą być prezentowane w taki sposób, aby można było je wykorzystać.
Parametry populacji i próby
N to populacja ogólna, która jest podzielona na warstwy N 1, N 2 i tak dalej.
Warstwa reprezentują obiekty jednorodne pod względem cech statystycznych (np. populacja podzielona jest na warstwy według grup wiekowych lub klas społecznych; przedsiębiorstwa – według branży). W tym przypadku próbki nazywane są warstwowymi.
N - wielkość próbki.
Wnioski statystyczne z badania opierają się na rozkładzie zmiennej losowej X, natomiast zaobserwowane wartości x 1, x 2, x 3 nazywane są realizacjami zmiennej losowej x.
Rozkład zmiennej losowej X w populacji ogólnej ma charakter teoretyczny, idealny, a jej przykładowy odpowiednik jest rozkładem empirycznym
Dla próbki funkcja rozkładu jest trudna, a czasami niemożliwa do wyznaczenia, dlatego parametry szacuje się na podstawie danych empirycznych, a następnie podstawiamy je do wyrażenia analitycznego opisującego rozkład teoretyczny. W tym przypadku założenie o rodzaju rozkładu może być statystycznie poprawne lub błędne.
W każdym razie rozkład empiryczny zrekonstruowany na podstawie próbki tylko w przybliżeniu charakteryzuje rozkład prawdziwy.
Najważniejszymi parametrami rozkładów są oczekiwania matematyczneA i wariancja σ 2- miara rozproszenia danych.
Odchylenie standardoweσ - stopień odchylenia danych lub zbiorów obserwacyjnych od wartości średniej.
Zadanie 3. Michaił i jego przyjaciele postanowili zmierzyć wysokość swoich psów (w kłębie). Znajdź: wartość średnia; odchylenie wzrostu.

Rozwiązanie
Matematyczną wartość oczekiwaną lub średnią można znaleźć korzystając ze wzoru:
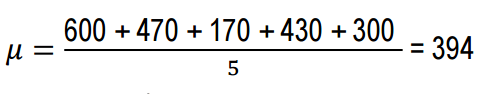
Teraz obliczmy odchylenie wzrostu każdego psa od średniej lub oczekiwań matematycznych, czyli obliczymy rozproszenie.
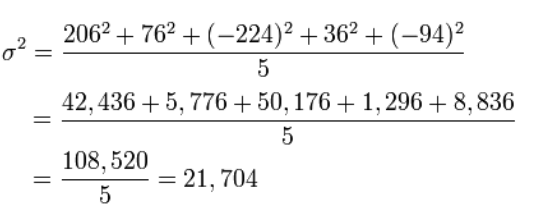

Odchylenie standardowe to po prostu pierwiastek kwadratowy z wariancji.
σ \ = 147,32
Zatem znając odchylenie standardowe, wiemy, co oznacza „normalny wzrost” oraz czym jest pies bardzo wysoki i bardzo mały.
Odpowiedź: 394, 21 704; 147,32.
Zadanie 4. Obserwacja w laboratorium kontrolnym trwałości 50 lamp elektrycznych tej samej mocy, wybranych losowo z dużej partii lamp tej samej mocy wyprodukowanych przez zakład, doprowadziła do następujących danych o naruszeniu ustalonej gwarancjiczas spalania:
|
Odchylenie w H |
10 mały rozkład, który odzwierciedla rzeczywiste odchylenie t okres palenia żarówek z gwarancji. Rozwiązanie. Średnie odchylenie
Zatem pożądany rozkład normalny charakteryzuje się następującymi wartościami parametrów: a = 0,4;σ2 = 318; σ = 17,8. Stąd gęstość prawdopodobieństwa: Funkcja rozkładu odpowiadająca tej gęstości będzie wyglądać następująco: |

100 RUR bonus za pierwsze zamówienie
Wybierz rodzaj pracy Praca dyplomowa Praca kursowa Streszczenie Praca magisterska Sprawozdanie z praktyki Artykuł Sprawozdanie Recenzja Praca testowa Monografia Rozwiązywanie problemów Biznes plan Odpowiedzi na pytania Praca twórcza Esej Rysunek Eseje Tłumaczenie Prezentacje Pisanie na maszynie Inne Zwiększanie niepowtarzalności tekstu Praca magisterska Praca laboratoryjna On-line pomoc
Poznaj cenę
Populacja ogólna to cały statystyczny zbiór obiektów i/lub zjawisk życia społecznego badanych metodą doboru próby, które mają wspólne cechy jakościowe lub zmienne ilościowe.
Całkowita liczba obiektów obserwacji (ludzi, gospodarstw domowych, przedsiębiorstw, osiedli itp.) o określonym zestawie cech (płeć, wiek, dochód, liczba, obrót itp.), ograniczona w przestrzeni i czasie. Przykłady populacji:
- Wszyscy mieszkańcy Moskwy (10,6 mln osób według spisu z 2002 r.)
- Moskale płci męskiej (4,9 mln osób według spisu z 2002 r.)
- Podmioty prawne w Rosji (2,2 mln na początku 2005 r.)
- Punkty sprzedaży detalicznej artykułów spożywczych (20 tys. na początku 2008 r.) itp.
Prawidłowa definicja G.S. a jego charakterystyka jest niezwykle istotna przy wyborze projektu badawczego – strategii konstruowania próby reprezentatywnej ( cm.). Najważniejsze cechy G.S. są jego objętość i dostępność elementów do określenia.
Z punktu widzenia objętości zwyczajowo rozróżnia się skończoną i nieskończoną G.S. Podział ten ma charakter czysto techniczny; zależy od specyfiki procedur szacowania objętości i błędów reprezentatywnej próbki prawdopodobieństwa (losowej). Za te ostatnie uważa się G.S., których liczba jest porównywalna z wielkością próby. Jeżeli liczebność próby przekracza kilka procent populacji G.S., należy ocenić błąd próbkowania dostosowany do wielkości G.S.
G.S. nazywane są nieskończonymi, których objętość w porównaniu z objętością reprezentatywnej próbki losowej jest nieproporcjonalnie duża. Ściśle rzecz biorąc, wszyscy G.S. w naukach społecznych są skończone (nawet jeśli ich liczba wynosi kilka miliardów), ale w praktyce G.S. można uznać za nieskończoną, jeśli liczebność próby, zapewniająca akceptowalny poziom błędu, nie przekracza 1-2% jej wielkości. Czasami pojęcie nieskończoności wiąże się bezpośrednio z objętością G.S., na przykład ponad stu tysiącami obiektów.
G.S., do których przynależność jest oczywista lub łatwa do ustalenia, nazywane są specyficznymi. Dla konkretnego G.S. łatwo jest określić objętość i uzyskać w miarę pełną listę ich elementów – operat losowania (patrz ryc. Podstawa pobierania próbek). Przykładowo listę dorosłych mieszkańców miasta można uzyskać w urzędzie adresowym, a wykazy studentów w dużym mieście można uzyskać na uczelniach wyższych. Jeżeli konkretny G.S. jest bardzo duża (na przykład populacja kraju), można uzyskać listy dla wszystkich jego części strukturalnych. Konstrukcja reprezentatywnej próby losowej ( cm.) dla konkretnego G.S. technicznie zawsze możliwe; problemy mogą wynikać z braku czasu, wykwalifikowanego personelu lub zasobów materialnych.
G.S., których przynależność można ustalić jedynie w wyniku ukierunkowanych procedur lub specjalnych badań, nazywane są hipotetycznymi. Do takiego G.S. zaliczają się na przykład odbiorcy QMS (nie da się dowiedzieć, czy dana osoba widziała konkretną reklamę, jeśli się jej o to nie zapytasz), miłośnicy określonych rodzajów ryb akwariowych, znawcy wąskiego problemu itp. Aby określić objętość jakiegoś hipotetycznego G.S. Potrzebne są także specjalne badania. Możliwość skonstruowania reprezentatywnej próby losowej ( cm.) dla hipotetycznego G.S. duża objętość w wielu przypadkach wydaje się problematyczna.
PARAMETR POPULACJI- termin statystyczny używany do określenia dowolnej cechy ilościowej populacji ogólnej ( cm.). Wartość oczekiwana ( cm.), wariancja ( cm.), prawdopodobieństwo ( cm.) odpowiedź pozytywna, współczynnik korelacji pomiędzy dwiema zmiennymi losowymi ( cm.) to G.S.P. Podobne cechy próbki ( cm.) nazywane są statystykami próbek ( cm.).
Próbka (Próbna populacja) - zbiór przypadków (obiektów, obiektów, zdarzeń, próbek), przy zastosowaniu określonej procedury, wybranych z populacji ogólnej do udziału w badaniu.
Część populacji wybrana do badania w celu wyciągnięcia wniosków na temat całej populacji. Aby wniosek uzyskany z badania próby można było rozszerzyć na całą populację, próba musi posiadać cechę reprezentatywności.
Przykładowe cechy:
Charakterystyka jakościowa próby – kogo dokładnie wybieramy i jakie metody pobierania próbek stosujemy w tym celu.
Charakterystyka ilościowa próby – ile przypadków wybieramy, innymi słowy wielkość próby.
Wielkość próbki— liczba przypadków objętych próbą populacji. Ze względów statystycznych zaleca się, aby liczba przypadków wynosiła co najmniej 30-35.
Populacja statystyczna- zbiór jednostek, który ma charakter masowy, typowość, jednorodność jakościową i obecność zmienności.
Populacja statystyczna składa się z obiektów istniejących materialnie (Pracownicy, przedsiębiorstwa, kraje, regiony), jest przedmiotem.
Jednostka populacji— każdą konkretną jednostkę populacji statystycznej.
Ta sama populacja statystyczna może być jednorodna pod względem jednej cechy i niejednorodna pod względem innej.
Jednolitość jakościowa- podobieństwo wszystkich jednostek populacji na pewnych podstawach i odmienność na wszystkich innych.
W populacji statystycznej różnice między jedną jednostką populacji a drugą mają często charakter ilościowy. Ilościowe zmiany wartości cechy różnych jednostek populacji nazywane są zmiennością.
Odmiana cechy- ilościowa zmiana cechy (dla cechy ilościowej) podczas przejścia z jednej jednostki populacji do drugiej.
Podpisać- jest to właściwość, cecha charakterystyczna lub inna cecha jednostek, obiektów i zjawisk, którą można zaobserwować lub zmierzyć. Znaki dzielą się na ilościowe i jakościowe. Nazywa się zróżnicowanie i zmienność wartości cechy w poszczególnych jednostkach populacji zmiana.
Cech atrybutywnych (jakościowych) nie można wyrazić liczbowo (skład populacji według płci). Charakterystyki ilościowe mają wyraz liczbowy (skład populacji według wieku).
Indeks- jest to uogólniająca cecha ilościowa i jakościowa dowolnej właściwości jednostek lub agregatów jako całości w określonych warunkach czasu i miejsca.
Karta z punktami to zbiór wskaźników kompleksowo odzwierciedlających badane zjawisko.
Na przykład bada się wynagrodzenie:- Znak - płace
- Populacja statystyczna – wszyscy pracownicy
- Jednostką populacji jest każdy pracownik
- Jednorodność jakościowa - naliczone płace
- Odmiana znaku - ciąg liczb
Populacja i próbka z niej
Podstawą jest zbiór danych uzyskanych w wyniku pomiaru jednej lub większej liczby cech. Prawdziwie obserwowany zbiór obiektów, statystycznie reprezentowany przez liczbę obserwacji zmiennej losowej, to próbowanie i hipotetycznie istniejące (przypuszczalne) - ogólna populacja. Populacja może być skończona (liczba obserwacji N = stała) lub nieskończone ( N = ∞), a próbka z populacji jest zawsze wynikiem ograniczonej liczby obserwacji. Nazywa się liczbę obserwacji tworzących próbkę wielkość próbki. Jeśli wielkość próby jest wystarczająco duża (np. n → ∞) próbka jest brana pod uwagę duży w przeciwnym razie nazywa się to próbkowaniem ograniczona objętość. Próbka jest brana pod uwagę mały, jeżeli przy pomiarze jednowymiarowej zmiennej losowej liczebność próby nie przekracza 30 ( N<= 30 ) oraz podczas pomiaru kilku jednocześnie ( k) cechy w wielowymiarowej przestrzeni relacji N Do k nie przekracza 10 (nr< 10) . Przykładowe formularze seria odmian, jeśli jego członkowie są statystyki porządkowe, czyli przykładowe wartości zmiennej losowej X są uporządkowane rosnąco (rankingowo), nazywane są wartościami cechy opcje.
Przykład. Prawie ten sam losowo wybrany zestaw obiektów - banki komercyjne jednego okręgu administracyjnego Moskwy, można uznać za próbę z ogólnej populacji wszystkich banków komercyjnych w tym okręgu oraz jako próbę z ogólnej populacji wszystkich banków komercyjnych w Moskwie , a także próbkę z banków komercyjnych w kraju itp.
Podstawowe metody organizacji pobierania próbek
Wiarygodność wniosków statystycznych i miarodajna interpretacja wyników zależy od reprezentatywność próbki, tj. kompletność i adekwatność reprezentacji cech populacji ogólnej, w odniesieniu do której tę próbę można uznać za reprezentatywną. Badanie właściwości statystycznych populacji można zorganizować na dwa sposoby: za pomocą ciągły I nie ciągły. Ciągła obserwacja przewiduje zbadanie wszystkich jednostki badane całość, A obserwacja częściowa (selektywna).- tylko jego części.
Istnieje pięć głównych sposobów organizacji obserwacji próbki:
1. prosty losowy wybór, w którym obiekty są wybierane losowo z populacji obiektów (na przykład przy użyciu tabeli lub generatora liczb losowych), przy czym każda z możliwych próbek ma równe prawdopodobieństwo. Takie próbki nazywane są faktycznie losowe;
2. prosty wybór przy użyciu zwykłej procedury przeprowadza się za pomocą elementu mechanicznego (na przykład daty, dnia tygodnia, numeru mieszkania, liter alfabetu itp.), a uzyskane w ten sposób próbki nazywane są mechaniczny;
3. warstwowy selekcja polega na tym, że populacja ogólna objętości jest dzielona na subpopulacje lub warstwy (warstwy) objętości tak, że . Warstwy są obiektami jednorodnymi pod względem cech statystycznych (np. populacja jest podzielona na warstwy według grup wiekowych lub klas społecznych; przedsiębiorstwa według branży). W takim przypadku próbki nazywane są warstwowy(W przeciwnym razie, warstwowy, typowy, regionalizowany);
4. metody seryjny selekcja służy do formowania seryjny Lub próbki gniazd. Są wygodne, jeśli konieczne jest jednoczesne zbadanie „bloku” lub serii obiektów (na przykład partii towarów, produktów z określonej serii lub populacji podziału terytorialno-administracyjnego kraju). Wybór serii może odbywać się w sposób całkowicie losowy lub mechaniczny. W takim przypadku przeprowadzana jest pełna kontrola określonej partii towaru lub całej jednostki terytorialnej (budynku mieszkalnego lub bloku);
5. łączny selekcja (stopniowa) może łączyć kilka metod selekcji jednocześnie (na przykład warstwową i losową lub losową i mechaniczną); taka próbka nazywa się łączny.
Rodzaje selekcji
Przez umysł Wyróżnia się selekcję indywidualną, grupową i łączoną. Na indywidualny wybór Poszczególne jednostki populacji ogólnej są wybierane do populacji próbnej, przy czym wybór grupy- jakościowo jednorodne grupy (seria) jednostek, oraz łączony wybór obejmuje kombinację pierwszego i drugiego typu.
Przez metoda selekcja jest rozróżniana powtarzalne i niepowtarzalne próbka.
Powtarzalne nazywana selekcją, w której jednostka włączona do próby nie wraca do populacji pierwotnej i nie uczestniczy w dalszej selekcji; natomiast liczba jednostek w populacji ogólnej N ulega zmniejszeniu w procesie selekcji. Na powtarzający się wybór złapany w próbie jednostka po rejestracji wraca do populacji ogólnej, dzięki czemu zachowuje równe szanse, wraz z innymi jednostkami, do wykorzystania w dalszej procedurze selekcji; natomiast liczba jednostek w populacji ogólnej N pozostaje niezmieniona (metoda jest rzadko stosowana w badaniach społeczno-ekonomicznych). Jednak z dużym N (N → ∞) formuły dla powtarzalne selekcja zbliża się do tych dla powtarzający się selekcji, przy czym te drugie są praktycznie częściej stosowane ( N = stała).
Podstawowe charakterystyki parametrów populacji ogólnej i próbnej
Wnioski statystyczne z badania opierają się na rozkładzie zmiennej losowej i zaobserwowanych wartościach (x 1, x 2, ..., x n) nazywane są realizacjami zmiennej losowej X(n to wielkość próbki). Rozkład zmiennej losowej w populacji ogólnej jest teoretyczny, ma charakter idealny, podobnie jak jej odpowiednik w próbie empiryczny dystrybucja. Niektóre rozkłady teoretyczne są określone analitycznie, tj. ich opcje określić wartość funkcji rozkładu w każdym punkcie przestrzeni możliwych wartości zmiennej losowej. W przypadku próbki funkcja rozkładu jest trudna i dlatego czasami niemożliwa do ustalenia opcje są szacowane na podstawie danych empirycznych, a następnie podstawione do wyrażenia analitycznego opisującego rozkład teoretyczny. W tym przypadku założenie (lub hipoteza) dotyczące rodzaju rozkładu może być statystycznie poprawne lub błędne. W każdym razie rozkład empiryczny zrekonstruowany na podstawie próbki tylko w przybliżeniu charakteryzuje rozkład prawdziwy. Najważniejszymi parametrami dystrybucji są wartość oczekiwana i dyspersja.
Dystrybucje są ze swej natury ciągły I oddzielny. Najbardziej znaną dystrybucją ciągłą jest normalna. Przykładowymi analogami parametrów i dla niego są: wartość średnia i wariancja empiryczna. Spośród dyskretnych w badaniach społeczno-ekonomicznych, najczęściej stosowana alternatywa (dychotomiczna) dystrybucja. Matematyczny parametr oczekiwań tego rozkładu wyraża wartość względną (lub udział) jednostki populacji posiadające badaną cechę (jest to oznaczone literą); odsetek populacji, który nie posiada tej cechy, jest oznaczony literą q (q = 1 - p). Wariancja alternatywnego rozkładu ma również empiryczny odpowiednik.
W zależności od rodzaju rozkładu i sposobu doboru jednostek populacji, charakterystyki parametrów rozkładu obliczane są w różny sposób. Najważniejsze dla rozkładów teoretycznych i empirycznych podano w tabeli. 9.1.
Frakcja próbki k n Stosunek liczby jednostek w populacji próbnej do liczby jednostek w populacji ogólnej nazywa się:
kn = n/N.
Frakcja próbki w jest stosunkiem jednostek posiadających badaną cechę X do wielkości próbki N:
w = n n / n.
Przykład. W partii towaru zawierającej 1000 sztuk, przy próbie 5%. próbny udział k n w wartości bezwzględnej wynosi 50 jednostek. (n = N*0,05); jeśli w tej próbce zostaną znalezione 2 wadliwe produkty, wówczas współczynnik defektów próbek w wyniesie 0,04 (w = 2/50 = 0,04 lub 4%).
Ponieważ populacja próbna różni się od populacji ogólnej, istnieją błędy próbkowania.
Tabela 9.1 Główne parametry populacji ogólnej i próbnej
Błędy próbkowania
W każdym przypadku (ciągłym i selektywnym) mogą wystąpić błędy dwojakiego rodzaju: rejestracyjnego i reprezentatywności. Błędy rejestracja może mieć losowy I systematyczny postać. Losowy błędy mają wiele różnych, niemożliwych do kontrolowania przyczyn, są niezamierzone i zwykle się równoważą (na przykład zmiany w działaniu urządzenia spowodowane wahaniami temperatury w pomieszczeniu).
Systematyczny błędy są stronnicze, ponieważ naruszają zasady doboru obiektów do próbki (na przykład odchylenia w pomiarach przy zmianie ustawień urządzenia pomiarowego).
Przykład. Aby ocenić sytuację społeczną ludności miasta, planuje się przeprowadzić badanie wśród 25% rodzin. Jeżeli przy wyborze co czwartego mieszkania podstawą będzie jego liczba, istnieje niebezpieczeństwo wybrania wszystkich mieszkań tylko jednego typu (np. mieszkania jednopokojowe), co wprowadzi błąd systematyczny i zniekształci wyniki; bardziej preferowany jest losowy wybór numeru mieszkania, ponieważ błąd będzie losowy.
Błędy reprezentatywności są nieodłącznie związane jedynie z obserwacją próby, nie można ich uniknąć i powstają w wyniku tego, że populacja próbna nie odtwarza w pełni populacji ogólnej. Wartości wskaźników uzyskane z próby różnią się od wskaźników o tych samych wartościach w populacji ogólnej (lub uzyskanych w drodze ciągłej obserwacji).
Błąd próbkowania jest różnicą między wartością parametru w populacji a wartością jej próbki. Dla średniej wartości cechy ilościowej jest ona równa: , a dla udziału (charakterystyka alternatywna) - .
Błędy próbkowania są nieodłącznie związane tylko z obserwacjami próbek. Im większe są te błędy, tym bardziej rozkład empiryczny różni się od teoretycznego. Parametry rozkładu empirycznego są zmiennymi losowymi, dlatego błędy próbkowania są również zmiennymi losowymi, mogą przyjmować różne wartości dla różnych próbek i dlatego zwyczajowo oblicza się średni błąd.
Średni błąd próbkowania jest wielkością wyrażającą odchylenie standardowe średniej próbki od oczekiwań matematycznych. Wartość ta, z zastrzeżeniem zasady doboru losowego, zależy przede wszystkim od liczebności próby oraz od stopnia zmienności cechy: im większe i mniejsze jest zmienność cechy (a więc i jej wartość), tym mniejszy jest średni błąd próby . Zależność pomiędzy wariancjami populacji ogólnej i próbnej wyraża się wzorem:
te. gdy jest wystarczająco duży, możemy to założyć. Średni błąd próbkowania pokazuje możliwe odchylenia parametru populacji próbnej od parametru populacji ogólnej. W tabeli W tabeli 9.2 przedstawiono wyrażenia służące do obliczania średniego błędu próbkowania dla różnych metod organizacji obserwacji.
Tabela 9.2 Średni błąd (m) średniej próbki i proporcji dla różnych typów próbek
Gdzie jest średnią wariancji próbki wewnątrz grupy dla atrybutu ciągłego;
Średnia wariancji wewnątrzgrupowych proporcji;
— liczba wybranych serii, — całkowita liczba serii;
 ,
,
gdzie jest średnia serii th;
— ogólna średnia dla całej populacji próbnej dla cechy ciągłej;
 ,
,
gdzie jest udział cechy w szeregu th;
— całkowity udział cechy w całej populacji próby.
Jednakże wielkość błędu średniego można ocenić jedynie z pewnym prawdopodobieństwem P (P ≤ 1). Lapunow A.M. udowodnili, że rozkład średnich próby, a co za tym idzie ich odchylenia od średniej ogólnej, dla dostatecznie dużej liczby jest w przybliżeniu zgodny z prawem rozkładu normalnego, pod warunkiem, że populacja ogólna ma skończoną średnią i ograniczoną wariancję.
Matematycznie to stwierdzenie dotyczące średniej wyraża się jako:

a dla udziału wyrażenie (1) będzie miało postać:
Gdzie  -
Jest marginalny błąd próbkowania, który jest wielokrotnością średniego błędu próbkowania ,
a współczynnikiem krotności jest kryterium Studenta („współczynnik ufności”) zaproponowane przez W.S. Gosset (pseudonim „Student”); wartości dla różnych wielkości próbek są przechowywane w specjalnej tabeli.
-
Jest marginalny błąd próbkowania, który jest wielokrotnością średniego błędu próbkowania ,
a współczynnikiem krotności jest kryterium Studenta („współczynnik ufności”) zaproponowane przez W.S. Gosset (pseudonim „Student”); wartości dla różnych wielkości próbek są przechowywane w specjalnej tabeli.

Dlatego wyrażenie (3) można odczytać następująco: z prawdopodobieństwem P = 0,683 (68,3%) można postawić tezę, że różnica między średnią próbną a średnią ogólną nie przekroczy jednej wartości błędu średniego m(t=1), z prawdopodobieństwem P = 0,954 (95,4%)- aby nie przekroczyła wartości dwóch błędów średnich m (t = 2) , z prawdopodobieństwem P = 0,997 (99,7%)- nie przekroczy trzech wartości m (t = 3) . Zatem prawdopodobieństwo, że różnica ta przekroczy trzykrotność błędu średniego, określa się według poziom błędu i nie wynosi nic więcej 0,3% .
W tabeli 9.3 pokazuje wzory do obliczania maksymalnego błędu próbkowania.
Tabela 9.3 Błąd krańcowy (D) próbki dla średniej i proporcji (p) dla różnych typów obserwacji próbki
Uogólnianie wyników próby na populację
Ostatecznym celem obserwacji próby jest scharakteryzowanie populacji ogólnej. Przy małych próbach empiryczne szacunki parametrów ( i ) mogą znacznie odbiegać od ich prawdziwych wartości ( i ). Dlatego istnieje potrzeba ustalenia granic, w których mieszczą się prawdziwe wartości ( i ) dla przykładowych wartości parametrów ( i ).
Przedział ufności dowolnego parametru θ populacji ogólnej jest losowym zakresem wartości tego parametru, który z prawdopodobieństwem bliskim 1 ( niezawodność) zawiera prawdziwą wartość tego parametru.
Marginalny błąd próbki Δ pozwala określić wartości graniczne cech populacji ogólnej i jej przedziały ufności, które są równe:
Konkluzja przedział ufności otrzymane przez odejmowanie maksymalny błąd ze średniej próbki (udziału), a górną poprzez jej dodanie.
Przedział ufności dla średniej wykorzystuje się maksymalny błąd próbkowania i dla danego poziomu ufności wyznacza się ze wzoru:
Oznacza to, że z danym prawdopodobieństwem R, który nazywany jest poziomem ufności i jest jednoznacznie określany przez wartość T, można argumentować, że prawdziwa wartość średniej mieści się w przedziale od ![]() , a prawdziwa wartość udziału mieści się w przedziale od
, a prawdziwa wartość udziału mieści się w przedziale od
Przy obliczaniu przedziału ufności dla trzech standardowych poziomów ufności P = 95%, P = 99% i P = 99,9% wartość jest wybierana przez . Zastosowania w zależności od liczby stopni swobody. Jeśli wielkość próbki jest wystarczająco duża, wówczas wartości odpowiadają tym prawdopodobieństwu T są równe: 1,96, 2,58 I 3,29 . Zatem marginalny błąd próbkowania pozwala nam określić wartości graniczne cech populacji i ich przedziały ufności:
Rozkład wyników obserwacji próby na populację ogólną w badaniach społeczno-ekonomicznych ma swoją specyfikę, gdyż wymaga pełnej reprezentacji wszystkich jej typów i grup. Podstawą możliwości takiego podziału jest kalkulacja względny błąd:

Gdzie Δ % - względny maksymalny błąd próbkowania; , .
Istnieją dwie główne metody rozszerzania obserwacji próbki na populację: metoda bezpośredniego przeliczenia i współczynnika.
Istota bezpośrednia konwersja polega na pomnożeniu średniej próbki!!\overline(x) przez wielkość populacji.
Przykład. Niech metodą doboru próby oszacowana zostanie średnia liczba małych dzieci w mieście i wyniesie jedną osobę. Jeżeli w mieście jest 1000 młodych rodzin, liczbę potrzebnych miejsc w miejskich żłobkach oblicza się mnożąc tę średnią przez liczebność populacji ogólnej N = 1000, tj. będzie miał 1200 miejsc.
Metoda szans Wskazane jest stosowanie w przypadku prowadzenia obserwacji selektywnej w celu doprecyzowania danych z obserwacji ciągłej.
Stosowana jest następująca formuła:
gdzie wszystkie zmienne to wielkość populacji:
Wymagana wielkość próbki
Tabela 9.4 Wymagana wielkość próby (n) dla różnych typów organizacji obserwacji próbek
Planując obserwację próbki z ustaloną wartością dopuszczalnego błędu próbkowania, konieczne jest prawidłowe oszacowanie wymaganego wielkość próbki. Wielkość tę można wyznaczyć na podstawie błędu dopuszczalnego podczas obserwacji próbki w oparciu o dane prawdopodobieństwo gwarantujące dopuszczalną wartość poziomu błędu (uwzględniając sposób organizacji obserwacji). Wzory na określenie wymaganej wielkości próby n można łatwo uzyskać bezpośrednio ze wzorów na maksymalny błąd próbkowania. Zatem z wyrażenia na błąd krańcowy:
wielkość próbki jest określana bezpośrednio N:
Wzór ten pokazuje, że w miarę zmniejszania się maksymalnego błędu próbkowania Δ wymagana wielkość próby znacznie wzrasta, co jest proporcjonalne do wariancji i kwadratu testu t-Studenta.
Dla określonego sposobu organizacji obserwacji wymaganą liczebność próby oblicza się według wzorów podanych w tabeli. 9.4.
Praktyczne przykłady obliczeń
Przykład 1. Obliczenie wartości średniej i przedziału ufności dla ciągłej charakterystyki ilościowej.
Aby ocenić szybkość rozliczeń z wierzycielami, w banku przeprowadzono losową próbę 10 dokumentów płatniczych. Ich wartości okazały się równe (w dniach): 10; 3; 15; 15; 22; 7; 8; 1; 19; 20.
Konieczne z prawdopodobieństwem P = 0,954 określić błąd krańcowy Δ średnia próbki i granice ufności średniego czasu obliczeń.
Rozwiązanie. Wartość średnią oblicza się na podstawie wzoru z tabeli. 9.1 dla próbki populacji
![]()
Wariancję oblicza się na podstawie wzoru z tabeli. 9.1.
![]()
Średni błąd kwadratowy dnia.
Średni błąd oblicza się ze wzoru:
![]()
te. średnia jest x ± m = 12,0 ± 2,3 dni.
Rzetelność średniej była
![]()
Maksymalny błąd obliczamy korzystając ze wzoru z tabeli. 9.3 w przypadku ponownego pobierania próbek, ponieważ wielkość populacji jest nieznana, oraz dla P = 0,954 poziom pewności.
Zatem średnia wartość wynosi `x ± D = `x ± 2m = 12,0 ± 4,6, tj. jego rzeczywista wartość mieści się w przedziale od 7,4 do 16,6 dnia.
Korzystanie ze stołu t-Studenta. Aplikacja pozwala stwierdzić, że dla n = 10 – 1 = 9 stopni swobody otrzymana wartość jest wiarygodna na poziomie istotności 0,001 £, tj. uzyskana wartość średnia jest znacząco różna od 0.
Przykład 2. Oszacowanie prawdopodobieństwa (udziału ogólnego) s. 10-10
Mechaniczna metoda doboru próby, polegająca na badaniu statusu społecznego 1000 rodzin, ujawniła, że odsetek rodzin o niskich dochodach był w = 0,3 (30%)(próbka była 2% , tj. n/N = 0,02). Wymagane przy poziomie ufności p = 0,997 określić wskaźnik R rodzin o niskich dochodach w całym regionie.
Rozwiązanie. Na podstawie przedstawionych wartości funkcji Ф(t) znaleźć dla danego poziomu ufności P = 0,997 oznaczający t = 3(patrz wzór 3). Marginalny błąd ułamka w określić na podstawie wzoru z tabeli. 9.3 dla pobierania próbek jednorazowych (pobieranie mechaniczne jest zawsze jednorazowe):
Maksymalny względny błąd próbkowania w % będzie:
Prawdopodobieństwo (ogólny udział) rodzin o niskich dochodach w regionie będzie wynosić р=w±Δw, a granice ufności p oblicza się na podstawie podwójnej nierówności:
w — Δ w ≤ p ≤ w — Δ w, tj. prawdziwa wartość p leży w:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Zatem z prawdopodobieństwem 0,997 można stwierdzić, że udział rodzin o niskich dochodach wśród wszystkich rodzin w województwie waha się od 28,6% do 31,4%.
Przykład 3. Obliczenie wartości średniej i przedziału ufności dla cechy dyskretnej określonej szeregiem przedziałów.
W tabeli 9,5. określony jest podział wniosków o produkcję zamówień według terminu ich realizacji przez przedsiębiorstwo.
Tabela 9.5 Rozkład obserwacji według czasu pojawienia sięRozwiązanie. Średni czas realizacji zamówień obliczany jest według wzoru:
Średni okres będzie wynosił:
= (3*20 + 9*80 + 24*60 + 48*20 + 72*20)/200 = 23,1 miesiąca.
Tę samą odpowiedź otrzymamy, jeśli wykorzystamy dane na p i z przedostatniej kolumny tabeli. 9.5, korzystając ze wzoru:
Należy zauważyć, że środek przedziału ostatniej gradacji znajduje się poprzez sztuczne uzupełnienie go o szerokość przedziału poprzedniej gradacji równą 60 - 36 = 24 miesiące.
Wariancję oblicza się za pomocą wzoru
![]()
Gdzie x ja- środek serii interwałowej.
Dlatego!!\sigma = \frac (20^2 + 14^2 + 1 + 25^2 + 49^2)(4), a błąd średniokwadratowy wynosi .
Średni błąd oblicza się stosując wzór miesięczny, tj. średnia wartość wynosi!!\overline(x) ± m = 23,1 ± 13,4.
Maksymalny błąd obliczamy korzystając ze wzoru z tabeli. 9,3 dla selekcji powtórnej, ponieważ wielkość populacji jest nieznana, dla poziomu ufności 0,954:
Zatem średnia wynosi:
te. jego prawdziwa wartość mieści się w przedziale od 0 do 50 miesięcy.
Przykład 4. Aby określić szybkość rozliczeń z wierzycielami N = 500 przedsiębiorstw korporacyjnych w banku komercyjnym, konieczne jest przeprowadzenie badania reprezentacyjnego z wykorzystaniem losowej, niepowtarzalnej metody doboru. Wyznacz wymaganą liczebność próby n tak, aby z prawdopodobieństwem P = 0,954 błąd średniej próby nie przekraczał 3 dni, jeżeli szacunki próbne wykazały, że odchylenie standardowe s wynosiło 10 dni.
Rozwiązanie. Aby określić liczbę wymaganych badań n, skorzystamy ze wzoru na jednorazowy wybór z tabeli. 9.4:

W nim wartość t jest określana na poziomie ufności P = 0,954. Jest ona równa 2. Wartość średnia kwadratowa wynosi s = 10, wielkość populacji wynosi N = 500, a maksymalny błąd średniej wynosi Δ x = 3. Podstawiając te wartości do wzoru, otrzymujemy:
![]()
te. Wystarczy skompletować próbę 41 przedsiębiorstw, aby oszacować wymagany parametr – szybkość rozliczeń z wierzycielami.
Populacja - zbiór osób, o których socjolog stara się uzyskać informacje w swoich badaniach. W zależności od tego, jak szeroki jest temat badań, populacja będzie równie szeroka.
Próbna populacja – model zredukowanej populacji; ci, którym socjolog rozdaje kwestionariusze, nazywani respondentami, którzy w końcu są przedmiotem badań socjologicznych.
O tym, kto dokładnie zostanie włączony do populacji ogólnej, decydują cele badania, a o tym, kto zostanie włączony do populacji próbnej, decydują metody matematyczne. Jeśli socjolog zamierza spojrzeć na wojnę w Afganistanie oczami jej uczestników, do ogólnej populacji należeć będą wszyscy żołnierze afgańscy, ale będzie musiał przeprowadzić wywiad z niewielką częścią – populacją próbną. Aby próba dokładnie odzwierciedlała populację ogólną, socjolog kieruje się zasadą: każdy żołnierz afgański, niezależnie od miejsca zamieszkania, miejsca pracy, stanu zdrowia i innych okoliczności, musi mieć takie samo prawdopodobieństwo znalezienia się w próbie populacja.
Kiedy socjolog już zdecydował, z kim chce przeprowadzić wywiad, ustala ramka próbkowania. Następnie zostaje rozstrzygnięta kwestia rodzaju pobierania próbek.
Próbki są podzielone na trzy duże klasy:
A) solidny(spisy powszechne, referenda). Badaniom podlegają wszystkie jednostki populacji;
B) losowy;
V) nie losowo.
Z kolei losowe i nielosowe typy próbkowania dzielą się na kilka typów.
Losowe obejmują:
1) probabilistyczny;
2) systematyczny;
3) strefowy (warstwowy);
4) zagnieżdżanie
Do nielosowych należą:
1) "spontaniczny";
2) kontyngent;
3) metoda „tablicy głównej”.
Pełna i dokładna lista jednostek w formularzach populacji próbnej ramka próbkowania . Elementy przeznaczone do selekcji nazywane są jednostki selekcji . Jednostki próby mogą być takie same jak jednostki obserwacji, ponieważ jednostka obserwacji uważa się za element populacji ogólnej, od którego bezpośrednio zbierane są informacje. Zazwyczaj jednostką obserwacji jest jednostka. Wyboru z listy najlepiej dokonać poprzez numerację jednostek i skorzystanie z tabeli liczb losowych, chociaż często stosuje się metodę quasi-losową, gdy co n-ty element jest pobierany z prostej listy.
Jeżeli operat losowania zawiera listę jednostek próby, wówczas struktura losowania zakłada pogrupowanie ich według pewnych ważnych cech, na przykład rozkładu osób według zawodu, kwalifikacji, płci lub wieku. Jeśli na przykład w populacji ogólnej jest 30% młodzieży, 50% osób w średnim wieku i 20% osób starszych, to w populacji próby należy zachować te same proporcje procentowe trzech grup wiekowych. Do grup wiekowych można dodać klasy, płeć, narodowość itp. Dla każdego z nich ustalane są proporcje procentowe w populacji ogólnej i próbnej. Zatem, ramka próbkowania – procentowe proporcje cech obiektu, na podstawie których zestawiana jest populacja próbna.
Jeśli typ próby mówi nam, w jaki sposób ludzie trafiają do populacji próbnej, wówczas wielkość próby mówi nam, ilu z nich się tam znalazło.
Wielkość próbki – liczba jednostek w populacji próbnej. Ponieważ populacja próbna jest częścią populacji ogólnej wybranej specjalnymi metodami, jej liczebność jest zawsze mniejsza niż wielkość populacji ogólnej. Dlatego tak ważne jest, aby część nie zniekształcała idei całości, czyli ją reprezentowała.
Na wiarygodność danych wpływają nie cechy ilościowe populacji próby (jej wielkość), ale cechy jakościowe populacji ogólnej - stopień jej jednorodności. Rozbieżność między populacją ogólną a populacją próbną nazywa się błąd reprezentatywności , dopuszczalne odchylenie – 5%.
Oto kilka sposobów uniknięcia błędu:
każda jednostka w populacji musi mieć równe prawdopodobieństwo znalezienia się w próbie;
zaleca się selekcję spośród populacji jednorodnych;
musisz znać cechy populacji;
Przy kompilowaniu próby populacji należy wziąć pod uwagę błędy przypadkowe i systematyczne.
Jeżeli populacja próbna (próbka) zostanie skompletowana prawidłowo, to socjolog uzyskuje wiarygodne wyniki, charakteryzujące całą populację.
Jakie są główne metody pobierania próbek?
Mechaniczna metoda pobierania próbek, gdy wymagana liczba respondentów jest wybierana z ogólnej listy populacji ogólnej w regularnych odstępach czasu (np. co 10).
Metoda próbkowania seryjnego. W tym przypadku populację ogólną dzieli się na jednorodne części i z każdej z nich wybiera się proporcjonalnie jednostki analizy (np. 20% mężczyzn i kobiet w przedsiębiorstwie).
Metoda próbkowania skupień. Jednostką selekcji nie są poszczególni respondenci, ale grupy, w których następuje późniejsze ciągłe badanie. Próba ta będzie reprezentatywna, jeśli skład grup będzie podobny (np. po jednej grupie studentów z każdego strumienia wydziału uniwersyteckiego).
Główna metoda tablicowa– badanie wśród 60–70% populacji ogólnej.
Metoda doboru kwotowego. Najbardziej złożona metoda, wymagająca określenia co najmniej czterech cech, według których dobierani są respondenci. Zwykle używany w przypadku dużej populacji.
http://www.hi-edu.ru/e-books/xbook096/01/index.html?part-011.htm– bardzo przydatna strona!
Główną metodą statystyczną jest metoda doboru próby. Jest to naturalne, gdyż objętość badanych obiektów jest zwykle nieskończona (a nawet jeśli jest skończona, bardzo trudno jest uporządkować wszystkie obiekty, trzeba zadowolić się tylko ich częścią, selekcją).
Populacje ogólne i próbne
Populacja ogólna to ogół wszystkich pierwiastków badanych w danym eksperymencie.
Próbna populacja (lub próbka) to skończony zbiór obiektów wybranych losowo z populacji.
Objętość populacji (próbnej lub ogólnej) to liczba obiektów w tej populacji.
Przykład populacji ogólnej i próbnej
Załóżmy, że badamy psychologiczną predyspozycję danej osoby do podziału danego segmentu w stosunku do złotego podziału. Ponieważ pochodzenie samej koncepcji złotego podziału jest podyktowane antropometrią ludzkiego ciała, jasne jest, że w tym przypadku ogólna populacja to każde stworzenie antropogeniczne, które osiągnęło dojrzałość fizyczną i uzyskało ostateczne proporcje, to znaczy całe dorosła część ludzkości. Objętość tego zbioru jest praktycznie nieskończona.
Jeśli bada się tę predyspozycję wyłącznie w środowisku artystycznym, wówczas populację ogólną stanowią ludzie bezpośrednio związani z projektowaniem: artyści, architekci, projektanci. Takich osób jest również wiele i możemy założyć, że wielkość populacji ogólnej w tym przypadku jest również nieskończona.
W obu przypadkach w badaniach jesteśmy zmuszeni ograniczyć się do rozsądnej wielkości próby, wybierając jako przedstawicieli tej lub drugiej populacji studentów kierunków technicznych (jako osoby z dala od świata artystycznego) lub studentów wzornictwa (jako osoby bezpośrednio związane z światowe obrazy artystyczne).
Reprezentatywność
Głównym problemem metody doboru próby jest pytanie, na ile trafnie wybrane do badań obiekty z populacji ogólnej odzwierciedlają badane cechy populacji ogólnej, czyli kwestia reprezentatywności próby.
Tak więc próbkę nazywa się reprezentatywną, jeśli wystarczająco dokładnie odzwierciedla relacje ilościowe populacji ogólnej.
Oczywiście trudno powiedzieć, co dokładnie kryje się za niejasnym sformułowaniem dość dokładne. Kwestie reprezentatywności są na ogół najbardziej kontrowersyjne w każdym badaniu eksperymentalnym. Przykładów, które stały się już klasyczne, jest mnóstwo, gdy niewystarczająca reprezentatywność próby doprowadziła eksperymentatorów do absurdalnych wyników.
Z reguły kwestie reprezentatywności rozwiązuje się w drodze oceny eksperckiej, gdy środowisko naukowe akceptuje punkt widzenia grupy autorytatywnych ekspertów w sprawie poprawności badania.
Przykład reprezentatywności
Wróćmy do przykładu dzielenia odcinka. Problematyka reprezentatywności próbek leży tu u podstaw badania: w żadnym wypadku nie należy mieszać grup podmiotów ze względu na przynależność do środowiska artystycznego.
Rozkład statystyczny obserwowanej cechy
Częstotliwość obserwowanej wartości
Niech w wyniku badania próbki objętościowej zaobserwowany atrybut przyjmie wartości,, ..., a wartość została zaobserwowana raz, wartość została zaobserwowana raz itd., wartość została zaobserwowana raz. Następnie częstotliwość obserwowanej wartości nazywana jest liczbą, wartości są liczbami itp.
Względna częstotliwość obserwowanej wartości
Względna częstotliwość obserwowanej wartości to stosunek częstotliwości do wielkości próbki:
Oczywiste jest, że suma częstotliwości obserwowanej cechy powinna dać wielkość próby
a suma częstotliwości względnych powinna dać jedność:
Rozważania te można wykorzystać do kontroli podczas kompilowania tabel statystycznych. Jeżeli równości nie są spełnione, popełniono błąd podczas zapisywania wyników doświadczenia.
Rozkład statystyczny wartości obserwowanej
Rozkład statystyczny obserwowanej cechy to zgodność między obserwowanymi wartościami cechy a odpowiednimi częstotliwościami (lub częstotliwościami względnymi).
Z reguły rozkład statystyczny zapisywany jest w formie dwuwierszowej tabeli, w której w pierwszym wierszu wskazane są zaobserwowane wartości cechy, a w drugim odpowiednie częstotliwości (lub częstotliwości względne). linia:



