Popolazione generale e metodo di campionamento. Popolazioni generali e campione
La necessità di condurre studi campione può essere causata da vari motivi:
spesso uno studio completo del fenomeno studiato è troppo costoso e richiede tempo;
a volte l'opportunità di utilizzare le informazioni ricevute in uno studio completo può essere esaurita prima che il processo di preparazione sia completato;
in alcuni casi, a seguito del controllo della qualità del prodotto, l'oggetto in esame viene distrutto.
Esempio:
Supponiamo che la popolazione sia composta da tutti gli studenti della scuola (600 persone da 20 classi, 30 persone per classe). Oggetto di studio sono gli atteggiamenti nei confronti del fumo.
Popolazioneè un insieme di oggetti sui quali è necessario ottenere informazioni.
La popolazione generale è costituita da tutti gli oggetti che hanno qualità e proprietà che interessano il ricercatore. A volte la popolazione generale è l'intera popolazione adulta di una determinata regione (ad esempio, quando si studia l'atteggiamento dei potenziali elettori nei confronti di un candidato), molto spesso vengono specificati diversi criteri che determinano gli oggetti di studio. Ad esempio, le donne di età compresa tra 10 e 89 anni che usano una determinata marca di crema per le mani almeno una volta alla settimana e hanno un reddito di almeno 5mila rubli per membro della famiglia.
Campioneè un piccolo insieme di oggetti estratti dalla popolazione.
Una popolazione campione è il minimo richiesto per uno studio di risultati (casi, soggetti, oggetti, eventi, campioni) selezionati utilizzando una determinata procedura dalla popolazione generale.
Esempi:
identificare la reazione dei clienti dell'azienda alle innovazioni; tutti i clienti dell'azienda rappresentano la popolazione generale. I clienti che sono stati chiamati costituiscono un campione.
Quando si revisionano aziende con un gran numero di transazioni, ci si deve accontentare di studiare un numero selezionato di transazioni. Tutte le transazioni dell'impresa costituiscono la popolazione generale, quelle selezionate costituiscono il campione.
la popolazione generale è composta da tutti i coscritti di un determinato anno.
Tutte le lampade prodotte in un determinato periodo di tempo in una determinata impresa costituiscono una popolazione generale. Vengono scelte le lampade selezionate per il controllo.
Il campione può essere considerato rappresentativo o non rappresentativo. Il campione sarà rappresentativo quando si esamina un grande gruppo di persone, se all'interno di questo gruppo ci sono rappresentanti di diversi sottogruppi, questo è l'unico modo per trarre conclusioni corrette. .
La rappresentatività è la corrispondenza delle caratteristiche del campione con le caratteristiche della popolazione o della popolazione generale nel suo insieme. La rappresentatività determina la misura in cui è possibile generalizzare i risultati di uno studio utilizzando un particolare campione all'intera popolazione da cui è stato raccolto.
La rappresentatività può anche essere definita come la proprietà di una popolazione campione di rappresentare i parametri della popolazione generale che sono significativi dal punto di vista degli obiettivi della ricerca.
Esempio: Un campione di 60 studenti delle scuole superiori rappresenta la popolazione molto meno bene di un campione delle stesse 60 persone che comprende 3 studenti per ogni classe. La ragione principale di ciò è la disuguale distribuzione dell’età nelle classi. Di conseguenza, nel primo caso, la rappresentatività del campione è bassa, mentre nel secondo caso, la rappresentatività è elevata (a parità di altre condizioni). .
Compito 1. In una città di 253.000 elettori aventi diritto, ricerca le tendenze politiche dei futuri elettori.
Soluzione
Il campione può essere costruito intervistando un acquirente su 15 che esce da un grande centro commerciale. Un campione di questo tipo rifletterà le opinioni dei visitatori dei centri commerciali, ma è improbabile che rappresenti le opinioni di tutti i residenti della città.
Un altro metodo per costruire un campione è quello di condurre un sondaggio telefonico su ogni 100 abitanti della città, prelevando i numeri dall'elenco telefonico. Questo campionamento sistematico fornirà informazioni sulle opinioni di un gruppo di persone che hanno un telefono, sono a casa e rispondono al telefono. Ma non riflette le opinioni di tutti i residenti della città.
Un altro metodo per costruire un campione sarebbe quello di intervistare i partecipanti ad una manifestazione organizzata da diversi partiti politici. Tale campione fornirà informazioni sui residenti che partecipano attivamente alla vita politica della città.
Quindi, abbiamo bisogno di metodi per formare un campione che rappresenti l'intera popolazione, cioè il campione deve essere rappresentativo (rappresentativo).
Compito 2. Determinare se il campione è rappresentativo:
1) il numero di incidenti stradali nel mese di giugno, se è necessario compilare un rapporto statistico sugli incidenti avvenuti in città per l'anno;
2) residenti urbani nel calcolo del numero di automobili pro capite nel paese;
3) persone di età compresa tra 40 e 50 anni nel determinare la valutazione di un programma televisivo giovanile.
Soluzione
1) Il campione non è rappresentativo. In estate non c'è neve né ghiaccio sulle strade e questa è una delle principali cause di incidenti.
2) Il campione non è rappresentativo. È chiaro che in città circolano molte più automobili che nelle zone rurali. Questo deve essere preso in considerazione.
3) Il campione non è rappresentativo. È improbabile che le persone di età compresa tra i 40 ei 50 anni mostrino interesse per un programma rivolto a un pubblico giovanile. Quando si utilizza un campione di questo tipo, la valutazione potrebbe diminuire in modo significativo, ma ciò non rifletterà la situazione reale. Per formare una popolazione campione vengono utilizzati vari metodi di selezione. Le statistiche devono essere presentate in modo tale da poter essere utilizzate.
Parametri della popolazione e del campione
N è la popolazione generale, divisa negli strati N 1, N 2 e così via.
Strati rappresentano oggetti omogenei in termini di caratteristiche statistiche (ad esempio, la popolazione è divisa in strati per fasce di età o classe sociale; imprese - per settore). In questo caso i campioni vengono detti stratificati.
N - dimensione del campione.
Le conclusioni statistiche dello studio si basano sulla distribuzione della variabile casuale X, mentre i valori osservati x 1, x 2, x 3 sono chiamati realizzazioni della variabile casuale x.
La distribuzione di una variabile casuale X nella popolazione generale è di natura teorica, ideale, e il suo analogo campionario è una distribuzione empirica
Per un campione, la funzione di distribuzione è difficile e talvolta impossibile da determinare, quindi i parametri vengono stimati da dati empirici e quindi sostituiti in un'espressione analitica che descrive la distribuzione teorica. In questo caso, l'ipotesi sul tipo di distribuzione può essere statisticamente corretta o errata.
Ma in ogni caso la distribuzione empirica ricostruita dal campione caratterizza solo approssimativamente quella vera.
I parametri più importanti delle distribuzioni sono le aspettative matematicheUN e varianza σ2- misura della dispersione dei dati.
Deviazione standardσ - il grado di deviazione dei dati o degli insiemi osservativi dal valore medio.
Compito 3. Mikhail e i suoi amici hanno deciso di misurare l'altezza dei loro cani (al garrese). Trova: valore medio; deviazione della crescita.

Soluzione
L'aspettativa matematica o il valore medio può essere trovato utilizzando la formula:
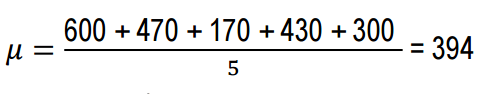
Ora calcoliamo la deviazione dell'altezza di ciascun cane dalla media o dall'aspettativa matematica, cioè calcoleremo la dispersione.
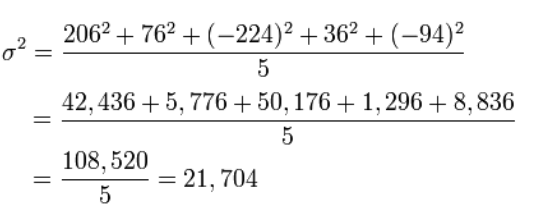

La deviazione standard è solo la radice quadrata della varianza.
σ \ = 147,32
Quindi, conoscendo la deviazione standard sappiamo cosa significa "altezza normale" e cos'è un cane molto alto e uno molto piccolo.
Risposta: 394, 21.704; 147.32.
Compito 4. L'osservazione in un laboratorio di controllo della durata di conservazione di 50 lampade elettriche della stessa potenza, prelevate a caso da un grande lotto di lampade della stessa potenza prodotte dall'impianto, ha portato ai seguenti dati sulla violazione della garanzia stabilitatempo di combustione:
|
Deviazione dentro H |
10 piccola distribuzione, che riflette la deviazione effettiva th il periodo di combustione delle lampadine dalla garanzia. Soluzione. Deviazione media
Pertanto, la distribuzione normale desiderata è caratterizzata dai seguenti valori dei parametri: a = 0,4;σ2 = 318; σ = 17,8. Da qui la densità di probabilità: La funzione di distribuzione corrispondente a questa densità sarà simile a: |

100 rupie bonus per il primo ordine
Seleziona il tipo di lavoro Lavoro di diploma Lavoro del corso Abstract Tesi di master Relazione pratica Articolo Report Revisione Lavoro di prova Monografia Problem solving Business plan Risposte alle domande Lavoro creativo Saggio Disegno Saggi Traduzione Presentazioni Dattilografia Altro Aumentare l'unicità del testo Tesi di master Lavoro di laboratorio Aiuto on-line
Scopri il prezzo
La popolazione generale è l'insieme statistico degli oggetti e/o fenomeni della vita sociale studiati con il metodo del campionamento che presentano caratteristiche qualitative o variabili quantitative comuni.
Il numero totale di oggetti di osservazione (persone, famiglie, imprese, insediamenti, ecc.) con un determinato insieme di caratteristiche (sesso, età, reddito, numero, fatturato, ecc.), limitato nello spazio e nel tempo. Esempi di popolazioni:
- Tutti i residenti di Mosca (10,6 milioni di persone secondo il censimento del 2002)
- Moscoviti maschi (4,9 milioni di persone secondo il censimento del 2002)
- Persone giuridiche della Russia (2,2 milioni all'inizio del 2005)
- Punti vendita al dettaglio di prodotti alimentari (20mila all'inizio del 2008), ecc.
La definizione corretta di G.S. e le sue caratteristiche sono estremamente importanti per la scelta di un disegno di ricerca - una strategia per costruire un campione rappresentativo ( cm.). Le caratteristiche più importanti del G.S. sono il suo volume e la disponibilità di elementi per la determinazione.
Dal punto di vista del volume si è soliti distinguere tra G.S. finito e infinito. Questa divisione è puramente tecnica; è determinata dalle peculiarità delle procedure per stimare il volume e gli errori di un campione probabilistico rappresentativo (casuale). Quelli finali sono considerati G.S., il cui numero è paragonabile alla dimensione del campione. Se la dimensione del campione supera diverse percentuali della popolazione del S.G., l’errore di campionamento deve essere valutato aggiustato per la dimensione della popolazione del S.G.
I G.S. sono chiamati infiniti, il cui volume, rispetto al volume di un campione casuale rappresentativo, è sproporzionatamente grande. A rigor di termini, tutti i G.S. nelle scienze sociali sono finiti (anche se il loro numero è di diversi miliardi), ma in pratica G.S. può essere considerato infinito se la dimensione del campione, fornendo un livello di errore accettabile, non supera l'1-2% della sua dimensione. A volte il concetto di infinito è associato direttamente al volume del G.S., ad esempio più di centomila oggetti.
G.S., la cui appartenenza è evidente o facilmente accertabile, sono detti specifici. Per specifici G.S. è facile determinare il volume e ottenere un elenco relativamente completo dei suoi elementi: il quadro di campionamento (vedi. Base di campionamento). Ad esempio, è possibile ottenere un elenco dei residenti adulti di una città presso l'ufficio indirizzi e elenchi di studenti in una grande città presso le università. Se uno specifico G.S. è molto grande (ad esempio, la popolazione di un paese), è possibile ottenere elenchi per tutte le sue parti strutturali. Costruzione di un campione casuale rappresentativo ( cm.) per specifico G.S. tecnicamente sempre possibile; possono sorgere problemi dovuti alla mancanza di tempo, di personale qualificato o di risorse materiali.
G.S., la cui appartenenza potrà essere stabilita solo a seguito di procedure mirate o studi particolari, sono detti ipotetici. A tale G.S. includono, ad esempio, il pubblico del SGQ (è impossibile sapere se una persona ha visto uno spot pubblicitario specifico a meno che non gli si chieda a riguardo), gli amanti di alcuni tipi di pesci d'acquario, gli esperti di un problema specifico, ecc. Per determinare il volume di alcuni ipotetici G.S. Sono necessari anche studi specifici. Possibilità di costruire un campione casuale rappresentativo ( cm.) per l'ipotetico G.S. grandi volumi in molti casi sembrano problematici.
PARAMETRO DELLA POPOLAZIONE- un termine statistico utilizzato per designare qualsiasi caratteristica quantitativa di una popolazione generale ( cm.). Valore atteso ( cm.), varianza ( cm.), probabilità ( cm.) risposta positiva, coefficiente di correlazione tra due variabili casuali ( cm.) sono G.S.P. Caratteristiche del campione simili ( cm.) sono chiamati statistici campione ( cm.).
Campione (popolazione campione) - un insieme di casi (soggetti, oggetti, eventi, campioni), utilizzando una determinata procedura, selezionati dalla popolazione generale per partecipare allo studio.
Una parte di una popolazione selezionata per lo studio al fine di trarre conclusioni sull'intera popolazione. Affinché la conclusione ottenuta studiando il campione possa essere estesa all'intera popolazione, il campione deve possedere proprietà di rappresentatività.
Caratteristiche del campione:
Caratteristiche qualitative del campione: chi scegliamo esattamente e quali metodi di campionamento utilizziamo per questo.
Caratteristiche quantitative del campione: quanti casi selezioniamo, in altre parole, dimensione del campione.
Misura di prova— il numero di casi inclusi nella popolazione campione. Per ragioni statistiche, si raccomanda che il numero di casi sia almeno 30-35.
Popolazione statistica- un insieme di unità che hanno carattere di massa, tipicità, omogeneità qualitativa e presenza di variazione.
La popolazione statistica è costituita da oggetti materialmente esistenti (dipendenti, imprese, paesi, regioni), è un oggetto.
Unità della popolazione— ciascuna unità specifica di una popolazione statistica.
La stessa popolazione statistica può essere omogenea in una caratteristica ed eterogenea in un'altra.
Uniformità qualitativa- somiglianza di tutte le unità della popolazione su alcune basi e dissomiglianza su tutte le altre.
In una popolazione statistica, le differenze tra un'unità di popolazione e l'altra sono spesso di natura quantitativa. I cambiamenti quantitativi nei valori di una caratteristica di diverse unità di una popolazione sono chiamati variazione.
Variazione di un tratto- un cambiamento quantitativo in una caratteristica (per una caratteristica quantitativa) durante la transizione da un'unità della popolazione a un'altra.
Cartello- questa è una proprietà, caratteristica o altra caratteristica di unità, oggetti e fenomeni che possono essere osservati o misurati. I segni si dividono in quantitativi e qualitativi. Si chiama diversità e variabilità del valore di una caratteristica nelle singole unità di una popolazione variazione.
Le caratteristiche attributive (qualitative) non possono essere espresse numericamente (composizione della popolazione per genere). Le caratteristiche quantitative hanno un'espressione numerica (composizione della popolazione per età).
Indice- si tratta di una caratteristica quantitativa e qualitativa generalizzante di qualsiasi proprietà di unità o aggregati nel loro insieme in specifiche condizioni di tempo e luogo.
Scheda segnapuntiè un insieme di indicatori che riflettono in modo completo il fenomeno oggetto di studio.
Ad esempio, lo stipendio viene studiato:- Segno: salario
- Popolazione statistica: tutti i dipendenti
- L'unità della popolazione è ogni dipendente
- Omogeneità qualitativa - salari maturati
- Variazione di un segno: una serie di numeri
Popolazione e campione da essa
La base è un insieme di dati ottenuti come risultato della misurazione di una o più caratteristiche. Un insieme di oggetti realmente osservati, rappresentato statisticamente da un numero di osservazioni di una variabile casuale, lo è campionamento, e l'ipoteticamente esistente (congetturale) - popolazione generale. La popolazione può essere finita (numero di osservazioni N = cost) o infinito ( N = ∞), e un campione di una popolazione è sempre il risultato di un numero limitato di osservazioni. Viene chiamato il numero di osservazioni che formano un campione misura di prova. Se la dimensione del campione è sufficientemente grande ( n → ∞) viene considerato il campione grande, altrimenti si parla di campionamento volume limitato. Il campione viene considerato piccolo, se quando si misura una variabile casuale unidimensionale la dimensione del campione non supera 30 ( N<= 30 ), e quando si misurano più simultaneamente ( K) caratteristiche nello spazio delle relazioni multidimensionali N A K non eccede 10 (n/k< 10) . Il campione si forma serie di variazioni, se i suoi membri lo sono statistica ordinale, cioè valori campione della variabile casuale X sono ordinati in ordine crescente (classificato), vengono chiamati i valori della caratteristica opzioni.
Esempio. Quasi lo stesso insieme di oggetti selezionati casualmente - banche commerciali di un distretto amministrativo di Mosca, può essere considerato come un campione della popolazione generale di tutte le banche commerciali in questo distretto e come un campione della popolazione generale di tutte le banche commerciali di Mosca , nonché un campione delle banche commerciali del paese, ecc.
Metodi di base per l'organizzazione del campionamento
Dipende dall'affidabilità delle conclusioni statistiche e dall'interpretazione significativa dei risultati rappresentatività campioni, cioè completezza e adeguatezza della rappresentazione delle caratteristiche della popolazione generale, rispetto alla quale tale campione può ritenersi rappresentativo. Lo studio delle proprietà statistiche di una popolazione può essere organizzato in due modi: utilizzando continuo E non continuo. Osservazione continua comporta l'esame di tutti unità studiato totalità, UN osservazione parziale (selettiva).- solo parti di esso.
Esistono cinque modi principali per organizzare l’osservazione del campione:
1. selezione casuale semplice, in cui gli oggetti vengono selezionati casualmente da una popolazione di oggetti (ad esempio, utilizzando una tabella o un generatore di numeri casuali), con ciascuno dei possibili campioni avente la stessa probabilità. Tali campioni sono chiamati effettivamente casuale;
2. selezione semplice utilizzando una procedura regolare viene effettuata utilizzando un componente meccanico (ad esempio data, giorno della settimana, numero dell'appartamento, lettere dell'alfabeto, ecc.) e i campioni così ottenuti vengono chiamati meccanico;
3. stratificato la selezione consiste nel fatto che la popolazione generale del volume è divisa in sottopopolazioni o strati (strati) del volume in modo che . Gli strati sono oggetti omogenei in termini di caratteristiche statistiche (ad esempio, la popolazione è divisa in strati per classi di età o classi sociali; le imprese per branca di attività economica). In questo caso, vengono chiamati i campioni stratificato(Altrimenti, stratificato, tipico, regionalizzato);
4. metodi seriale la selezione viene utilizzata per formare seriale O campioni di nidi. Sono convenienti se è necessario rilevare contemporaneamente un "blocco" o una serie di oggetti (ad esempio un lotto di merci, prodotti di una determinata serie o la popolazione di una divisione amministrativa territoriale del paese). La selezione delle serie può essere effettuata in modo puramente casuale o meccanicamente. In questo caso viene effettuata un'ispezione completa di un determinato lotto di beni, oppure di un'intera unità territoriale (un edificio o un isolato residenziale);
5. combinato la selezione (a gradini) può combinare diversi metodi di selezione contemporaneamente (ad esempio, stratificato e casuale o casuale e meccanico); viene chiamato un tale campione combinato.
Tipi di selezione
Di mente Si distingue la selezione individuale, di gruppo e combinata. A selezione individuale singole unità della popolazione generale vengono selezionate nella popolazione campione, con selezione del gruppo- gruppi (serie) di unità qualitativamente omogenei, e selezione combinata implica una combinazione del primo e del secondo tipo.
Di metodo la selezione è distinta ripetuto e non ripetitivo campione.
Ripetibile chiamata selezione in cui un'unità inclusa nel campione non ritorna nella popolazione originaria e non partecipa a un'ulteriore selezione; mentre il numero di unità della popolazione generale N viene ridotto durante il processo di selezione. A ripetuto selezione preso nel campione, un'unità dopo la registrazione viene restituita alla popolazione generale e conserva quindi pari opportunità, insieme ad altre unità, di essere utilizzata in un'ulteriore procedura di selezione; mentre il numero di unità della popolazione generale N rimane invariato (il metodo è usato raramente nella ricerca socioeconomica). Tuttavia, con grandi N (N → ∞) formule per ripetibile la selezione si avvicina a quelle per ripetuto selezione e questi ultimi sono praticamente più usati ( N = cost).
Caratteristiche fondamentali dei parametri della popolazione generale e campionaria
Le conclusioni statistiche dello studio si basano sulla distribuzione della variabile casuale e sui valori osservati (x1, x2, ..., xn) sono chiamate realizzazioni della variabile casuale X(n è la dimensione del campione). La distribuzione di una variabile casuale nella popolazione generale è di natura teorica e ideale, così come lo è il suo analogo campionario empirico distribuzione. Alcune distribuzioni teoriche sono specificate analiticamente, ad es. loro opzioni determinare il valore della funzione di distribuzione in ogni punto dello spazio dei possibili valori della variabile casuale. Pertanto, per un campione, la funzione di distribuzione è difficile e talvolta impossibile da determinare opzioni vengono stimati a partire da dati empirici e poi sostituiti in un'espressione analitica che descrive la distribuzione teorica. In questo caso, l’ipotesi (o ipotesi) sul tipo di distribuzione può essere statisticamente corretto o errato. Ma in ogni caso la distribuzione empirica ricostruita dal campione caratterizza solo approssimativamente quella vera. I parametri di distribuzione più importanti sono valore atteso e dispersione.
Per loro natura, le distribuzioni lo sono continuo E discreto. La distribuzione continua più conosciuta è normale. Esempi di analoghi dei parametri e per esso sono: valore medio e varianza empirica. Tra quelli discreti nella ricerca socioeconomica, il più utilizzato alternativo (dicotomico) distribuzione. Il parametro di aspettativa matematica di questa distribuzione esprime il valore relativo (o condividere) unità della popolazione che presentano la caratteristica oggetto di studio (è indicata dalla lettera); la percentuale della popolazione che non ha questa caratteristica è indicata con la lettera q (q = 1 - p). La varianza della distribuzione alternativa ha anche un analogo empirico.
A seconda del tipo di distribuzione e del metodo di selezione delle unità di popolazione, le caratteristiche dei parametri di distribuzione vengono calcolate in modo diverso. Le principali distribuzioni teoriche ed empiriche sono riportate nella tabella. 9.1.
Frazione campione k n Il rapporto tra il numero di unità della popolazione campione e il numero di unità della popolazione generale si chiama:
kn = n/N.
Frazione campione wè il rapporto tra le unità che possiedono la caratteristica studiata X alla dimensione del campione N:
w = nn /n.
Esempio. In un lotto di merce contenente 1000 unità, con un campione del 5%. quota campione k n in valore assoluto è di 50 unità. (n = N*0,05); se in questo campione vengono trovati 2 prodotti difettosi, allora tasso di difetti del campione w sarà 0,04 (w = 2/50 = 0,04 o 4%).
Poiché la popolazione campione è diversa dalla popolazione generale, esistono errori di campionamento.
Tabella 9.1 Principali parametri della popolazione generale e del campione
Errori di campionamento
In ogni caso (continui e selettivi) possono verificarsi errori di due tipi: registrazione e rappresentatività. Errori registrazione possono avere casuale E sistematico carattere. Casuale gli errori sono costituiti da molte cause diverse e incontrollabili, sono involontari e di solito si compensano a vicenda (ad esempio, variazioni delle prestazioni del dispositivo a causa di sbalzi di temperatura nella stanza).
Sistematico gli errori sono distorti perché violano le regole per la selezione degli oggetti per il campione (ad esempio, deviazioni nelle misurazioni quando si modificano le impostazioni del dispositivo di misurazione).
Esempio. Per valutare la situazione sociale della popolazione della città si prevede di intervistare il 25% delle famiglie. Se la selezione di un appartamento su quattro si basa sul suo numero, c'è il pericolo di selezionare tutti gli appartamenti di un solo tipo (ad esempio monolocali), il che comporterà un errore sistematico e distorcerà i risultati; è preferibile scegliere il numero dell'appartamento per lotto, poiché l'errore sarà casuale.
Errori di rappresentatività sono inerenti solo all'osservazione del campione, non possono essere evitati e derivano dal fatto che la popolazione campione non riproduce completamente la popolazione generale. I valori degli indicatori ottenuti dal campione differiscono dagli indicatori degli stessi valori nella popolazione generale (o ottenuti attraverso l'osservazione continua).
Distorsione del campionamentoè la differenza tra il valore di un parametro nella popolazione e il suo valore campionario. Per il valore medio di una caratteristica quantitativa è pari a: , e per la quota (caratteristica alternativa) - .
Gli errori di campionamento sono inerenti solo alle osservazioni campionarie. Quanto più grandi sono questi errori, tanto più la distribuzione empirica differisce da quella teorica. I parametri della distribuzione empirica sono variabili casuali, quindi anche gli errori di campionamento sono variabili casuali, possono assumere valori diversi per campioni diversi e quindi è consuetudine calcolare errore medio.
Errore medio di campionamentoè una quantità che esprime la deviazione standard della media campionaria rispetto all'aspettativa matematica. Questo valore, soggetto al principio della selezione casuale, dipende principalmente dalla dimensione del campione e dal grado di variazione della caratteristica: quanto maggiore e minore è la variazione della caratteristica (e quindi del valore), tanto minore è l'errore medio di campionamento . La relazione tra le varianze della popolazione generale e del campione è espressa dalla formula:
quelli. quando abbastanza grande, possiamo supporre che . L'errore medio di campionamento mostra le possibili deviazioni del parametro della popolazione campione dal parametro della popolazione generale. Nella tabella La Tabella 9.2 mostra le espressioni per calcolare l'errore medio di campionamento per diversi metodi di organizzazione dell'osservazione.
Tabella 9.2 Errore medio (m) della media campionaria e proporzione per diversi tipi di campioni
Dov'è la media delle varianze campionarie all'interno del gruppo per un attributo continuo;
Media delle varianze intragruppo della proporzione;
— numero di serie selezionate, — numero totale di serie;
 ,
,
dov'è la media della serie-esima;
— la media complessiva dell'intera popolazione del campione per una caratteristica continua;
 ,
,
dove è la quota della caratteristica nella serie-esima;
— la quota totale della caratteristica nell'intera popolazione del campione.
Tuttavia, l’entità dell’errore medio può essere valutata solo con una certa probabilità P (P ≤ 1). Lyapunov A.M. ha dimostrato che la distribuzione delle medie campionarie, e quindi le loro deviazioni dalla media generale, per un numero sufficientemente grande obbedisce approssimativamente alla legge della distribuzione normale, a condizione che la popolazione generale abbia una media finita e una varianza limitata.
Matematicamente, questa affermazione per la media è espressa come:

e per la quota, l'espressione (1) assumerà la forma:
Dove  -
C'è errore marginale di campionamento, che è un multiplo dell'errore medio di campionamento ,
e il coefficiente di molteplicità è il criterio di Student (“coefficiente di confidenza”), proposto da W.S. Gosset (pseudonimo "Studente"); i valori per diverse dimensioni del campione sono memorizzati in una tabella speciale.
-
C'è errore marginale di campionamento, che è un multiplo dell'errore medio di campionamento ,
e il coefficiente di molteplicità è il criterio di Student (“coefficiente di confidenza”), proposto da W.S. Gosset (pseudonimo "Studente"); i valori per diverse dimensioni del campione sono memorizzati in una tabella speciale.

Pertanto l'espressione (3) può essere letta così: con probabilità P = 0,683 (68,3%) si può sostenere che la differenza tra il campione e la media generale non supererà un valore dell'errore medio m(t=1), con probabilità P = 0,954 (95,4%)- che non superi il valore di due errori medi m(t = 2) , con probabilità P = 0,997 (99,7%)- non supererà i tre valori m(t = 3) . Pertanto, viene determinata la probabilità che questa differenza superi tre volte l'errore medio livello di errore e non vale niente di più 0,3% .
Nella tabella 9.3 mostra le formule per il calcolo dell'errore massimo di campionamento.
Tabella 9.3 Errore marginale (D) del campione per la media e proporzione (p) per diversi tipi di osservazione del campione
Generalizzazione dei risultati del campione alla popolazione
L’obiettivo finale dell’osservazione del campione è caratterizzare la popolazione generale. Con campioni di piccole dimensioni, le stime empiriche dei parametri ( e ) possono discostarsi significativamente dai loro valori reali ( e ). Pertanto, è necessario stabilire i limiti entro i quali si trovano i valori reali ( e ) per i valori campione dei parametri ( e ).
Intervallo di confidenza di qualsiasi parametro θ della popolazione generale è l'intervallo casuale di valori di questo parametro, che con una probabilità vicina a 1 ( affidabilità) contiene il valore vero di questo parametro.
Errore marginale campioni Δ consente di determinare i valori limite delle caratteristiche della popolazione generale e dei loro intervalli di confidenza, che sono uguali:
Linea di fondo intervallo di confidenza ottenuto per sottrazione errore massimo dalla media campionaria (quota) e quella superiore sommandola.
Intervallo di confidenza per la media si utilizza il massimo errore campionario e per un dato livello di confidenza è determinato dalla formula:
Ciò significa che con una data probabilità R, che viene chiamato livello di confidenza ed è determinato in modo univoco dal valore T, si può sostenere che il vero valore della media rientra nell'intervallo da ![]() , e il valore reale dell'azione è compreso tra
, e il valore reale dell'azione è compreso tra
Quando si calcola l'intervallo di confidenza per tre livelli di confidenza standard P = 95%, P = 99% e P = 99,9% il valore è selezionato da . Applicazioni a seconda del numero di gradi di libertà. Se la dimensione del campione è sufficientemente grande, i valori corrispondono a queste probabilità T sono uguali: 1,96, 2,58 E 3,29 . Pertanto, l'errore marginale di campionamento ci consente di determinare i valori limite delle caratteristiche della popolazione e i loro intervalli di confidenza:
La distribuzione dei risultati dell'osservazione del campione alla popolazione generale nella ricerca socioeconomica ha le sue caratteristiche, poiché richiede una rappresentazione completa di tutti i suoi tipi e gruppi. La base per la possibilità di tale distribuzione è il calcolo errore relativo:

Dove Δ % - errore di campionamento massimo relativo; , .
Esistono due metodi principali per estendere un’osservazione campionaria a una popolazione: metodo del ricalcolo diretto e dei coefficienti.
Essenza conversione diretta consiste nel moltiplicare la media campionaria!!\overline(x) per la dimensione della popolazione.
Esempio. Supponiamo che il numero medio di bambini in città sia stimato con il metodo di campionamento e ammonti a una persona. Se in città ci sono 1.000 giovani famiglie, il numero di posti richiesti negli asili nido comunali si ottiene moltiplicando questa media per la dimensione della popolazione generale N = 1.000, ovvero avrà 1200 posti.
Metodo delle probabilità Si consiglia di utilizzarlo nel caso in cui venga effettuata l'osservazione selettiva per chiarire i dati dell'osservazione continua.
Viene utilizzata la seguente formula:
dove tutte le variabili rappresentano la dimensione della popolazione:
Dimensione del campione richiesta
Tabella 9.4 Dimensione del campione richiesta (n) per diversi tipi di organizzazione di osservazione del campione
Quando si pianifica un'osservazione del campione con un valore predeterminato dell'errore di campionamento ammissibile, è necessario stimare correttamente l'errore richiesto misura di prova. Questo volume può essere determinato sulla base dell'errore ammissibile durante l'osservazione del campione in base a una determinata probabilità che garantisce il valore ammissibile del livello di errore (tenendo conto del metodo di organizzazione dell'osservazione). Le formule per determinare la dimensione del campione richiesta n possono essere facilmente ottenute direttamente dalle formule per l'errore massimo di campionamento. Quindi, dall'espressione per l'errore marginale:
la dimensione del campione è determinata direttamente N:
Questa formula mostra che al diminuire dell'errore di campionamento massimo Δ la dimensione del campione richiesta aumenta in modo significativo, il che è proporzionale alla varianza e al quadrato del test t di Student.
Per un metodo specifico di organizzazione dell'osservazione, la dimensione del campione richiesta viene calcolata secondo le formule riportate nella tabella. 9.4.
Esempi pratici di calcolo
Esempio 1. Calcolo del valore medio e dell'intervallo di confidenza per una caratteristica quantitativa continua.
Per valutare la velocità di liquidazione con i creditori è stato effettuato presso la banca un campione casuale di 10 documenti di pagamento. I loro valori sono risultati uguali (in giorni): 10; 3; 15; 15; 22; 7; 8; 1; 19; 20.
Necessario con probabilità P = 0,954 determinare l’errore marginale Δ media campionaria e limiti di confidenza del tempo medio di calcolo.
Soluzione. Il valore medio viene calcolato utilizzando la formula della tabella. 9.1 per la popolazione campione
![]()
La varianza viene calcolata utilizzando la formula della tabella. 9.1.
![]()
Errore quadratico medio della giornata.
L'errore medio si calcola utilizzando la formula:
![]()
quelli. la media è x±m = 12,0±2,3 giorni.
L'affidabilità della media era
![]()
Calcoliamo l'errore massimo utilizzando la formula della tabella. 9.3 per il campionamento ripetuto, poiché la dimensione della popolazione non è nota, e per P = 0,954 livello di fiducia.
Pertanto, il valore medio è `x ± D = `x ± 2m = 12,0 ± 4,6, ovvero il suo vero valore è compreso tra 7,4 e 16,6 giorni.
Utilizzo della tabella T di uno studente. L'applicazione ci consente di concludere che per n = 10 - 1 = 9 gradi di libertà, il valore ottenuto è affidabile con un livello di significatività di £ 0,001, ovvero il valore medio risultante è significativamente diverso da 0.
Esempio 2. Stima della probabilità (quota generale) p.
Un metodo di campionamento meccanico per rilevare lo stato sociale di 1.000 famiglie ha rivelato che la percentuale di famiglie a basso reddito era w = 0,3 (30%)(il campione era 2% , cioè. n/N = 0,02). Obbligatorio con livello di confidenza p = 0,997 determinare l'indicatore R famiglie a basso reddito in tutta la regione.
Soluzione. In base ai valori della funzione presentati Ô(t) trovare per un dato livello di confidenza P = 0,997 Senso t = 3(vedi formula 3). Errore marginale della frazione w determinare con la formula dalla tabella. 9.3 per il campionamento non ripetitivo (il campionamento meccanico è sempre non ripetitivo):
Errore massimo di campionamento relativo in % sarà:
La probabilità (quota generale) di famiglie a basso reddito nella regione sarà ð=w±Δw, e i limiti di confidenza p sono calcolati in base alla doppia disuguaglianza:
w — Δ w ≤ p ≤ w — Δ w, cioè. il vero valore di p è compreso tra:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Pertanto, con una probabilità di 0,997 si può affermare che la quota di famiglie a basso reddito tra tutte le famiglie della regione varia dal 28,6% al 31,4%.
Esempio 3. Calcolo del valore medio e dell'intervallo di confidenza per una caratteristica discreta specificata da una serie di intervalli.
Nella tabella 9.5. viene specificata la distribuzione delle domande per la produzione di ordini in base ai tempi della loro attuazione da parte dell'impresa.
Tabella 9.5 Distribuzione delle osservazioni per tempo di comparsaSoluzione. Il tempo medio di completamento degli ordini viene calcolato utilizzando la formula:
Il periodo medio sarà:
= (3*20 + 9*80 + 24*60 + 48*20 + 72*20)/200 = 23,1 mesi.
Otteniamo la stessa risposta se utilizziamo i dati su p i della penultima colonna della tabella. 9.5, utilizzando la formula:
Si noti che la metà dell'intervallo dell'ultima gradazione si trova integrandola artificialmente con l'ampiezza dell'intervallo della gradazione precedente pari a 60 - 36 = 24 mesi.
La varianza viene calcolata utilizzando la formula
![]()
Dove x io- la metà della serie di intervalli.
Pertanto!!\sigma = \frac (20^2 + 14^2 + 1 + 25^2 + 49^2)(4), e l'errore quadratico medio è .
L'errore medio viene calcolato utilizzando la formula mensile, ovvero il valore medio è!!\overline(x) ± m = 23,1 ± 13,4.
Calcoliamo l'errore massimo utilizzando la formula della tabella. 9.3 per la selezione ripetuta, poiché la dimensione della popolazione non è nota, per un livello di confidenza di 0,954:
Quindi la media è:
quelli. il suo vero valore è compreso tra 0 e 50 mesi.
Esempio 4. Per determinare la velocità delle transazioni con i creditori di N = 500 società per azioni in una banca commerciale, è necessario condurre uno studio campione utilizzando un metodo di selezione casuale e non ripetitivo. Determinare la dimensione del campione richiesta n in modo che con probabilità P = 0,954 l'errore della media campionaria non superi i 3 giorni se le stime di prova hanno mostrato che la deviazione standard s era di 10 giorni.
Soluzione. Per determinare il numero di studi richiesti n, utilizzeremo la formula di selezione non ripetitiva dalla tabella. 9.4:

In esso, il valore t è determinato da un livello di confidenza di P = 0,954. È uguale a 2. Il valore quadratico medio è s = 10, la dimensione della popolazione è N = 500 e l'errore massimo della media è Δ x = 3. Sostituendo questi valori nella formula, otteniamo:
![]()
quelli. È sufficiente compilare un campione di 41 imprese per stimare il parametro richiesto: la velocità degli accordi con i creditori.
Popolazione - l'insieme di quelle persone sulle quali il sociologo cerca di ottenere informazioni nella sua ricerca. A seconda dell’ampiezza dell’argomento di ricerca, la popolazione sarà altrettanto ampia.
Popolazione campione – modello a popolazione ridotta; coloro ai quali il sociologo distribuisce i questionari, che vengono chiamati intervistati, che, infine, sono oggetto della ricerca sociologica.
Chi è incluso esattamente nella popolazione generale è determinato dagli obiettivi dello studio e chi è incluso nella popolazione campione è deciso con metodi matematici. Se un sociologo intende guardare la guerra afghana attraverso gli occhi dei suoi partecipanti, la popolazione generale includerà tutti i soldati afghani, ma dovrà intervistarne una piccola parte: la popolazione campione. Affinché il campione rifletta accuratamente la popolazione generale, il sociologo rispetta la regola: qualsiasi soldato afghano, indipendentemente dal luogo di residenza, luogo di lavoro, stato di salute e altre circostanze, deve avere la stessa probabilità di essere incluso nel campione popolazione.
Una volta che il sociologo ha deciso chi vuole intervistare, decide quadro di campionamento. Successivamente viene decisa la questione del tipo di campionamento.
I campioni sono divisi in tre grandi classi:
UN) solido(censimenti, referendum). Vengono censite tutte le unità della popolazione;
B) casuale;
V) Non casuale.
I tipi di campionamento casuale e non casuale sono a loro volta suddivisi in diverse tipologie.
Quelli casuali includono:
1) probabilistico;
2) sistematico;
3) suddiviso in zone (stratificato);
4) Nidificazione
Quelli non casuali includono:
1) "spontaneo";
2) quota;
3) metodo "array principale".
Un elenco completo e accurato di unità nei moduli della popolazione campione quadro di campionamento . Vengono richiamati gli elementi destinati alla selezione unità di selezione . Le unità di campionamento possono essere le stesse delle unità di osservazione perché unità di osservazione è considerato un elemento della popolazione generale da cui vengono raccolte direttamente le informazioni. Tipicamente l'unità di osservazione è l'individuo. La selezione da un elenco viene eseguita meglio numerando le unità e utilizzando una tabella di numeri casuali, sebbene venga spesso utilizzato un metodo quasi casuale, quando ogni n-esimo elemento viene preso da un elenco semplice.
Se il quadro di campionamento comprende un elenco di unità di campionamento, allora la struttura di campionamento implica il loro raggruppamento in base ad alcune caratteristiche importanti, ad esempio la distribuzione degli individui per professione, qualifica, genere o età. Se nella popolazione generale, ad esempio, ci sono il 30% di giovani, il 50% di persone di mezza età e il 20% di anziani, allora nella popolazione campione si devono osservare le stesse proporzioni percentuali delle tre età. È possibile aggiungere classi, sesso, nazionalità, ecc. alle età. Per ciascuno di essi vengono stabilite le proporzioni percentuali nella popolazione generale e nel campione. Così, quadro di campionamento – proporzioni percentuali delle caratteristiche dell'oggetto, sulla base delle quali viene compilata la popolazione campionaria.
Se il tipo di campione ci dice come le persone entrano nella popolazione campione, allora la dimensione del campione ci dice quanti di loro sono arrivati lì.
Misura di prova – numero di unità della popolazione campione. Poiché la popolazione campione è una parte della popolazione generale selezionata mediante metodi particolari, il suo volume è sempre inferiore al volume della popolazione generale. Pertanto, è così importante che la parte non distorca l'idea dell'insieme, cioè la rappresenti.
L'affidabilità dei dati non è influenzata dalle caratteristiche quantitative della popolazione campione (il suo volume), ma dalle caratteristiche qualitative della popolazione generale - il grado di omogeneità. Viene chiamata la discrepanza tra la popolazione generale e la popolazione campione errore di rappresentatività , deviazione consentita – 5%.
Ecco alcuni modi per evitare l'errore:
ogni unità della popolazione deve avere la stessa probabilità di essere inclusa nel campione;
è consigliabile selezionare tra popolazioni omogenee;
è necessario conoscere le caratteristiche della popolazione;
Quando si compila un campione di popolazione, è necessario tenere conto degli errori casuali e sistematici.
Se la popolazione campione (campione) viene elaborata correttamente, il sociologo ottiene risultati affidabili che caratterizzano l'intera popolazione.
Quali sono i principali metodi di campionamento?
Metodo di campionamento meccanico, quando il numero richiesto di intervistati viene selezionato dall'elenco generale della popolazione generale a intervalli regolari (ad esempio, ogni 10).
Metodo di campionamento seriale. In questo caso la popolazione generale viene suddivisa in parti omogenee e da ciascuna vengono selezionate proporzionalmente le unità di analisi (ad esempio, il 20% degli uomini e delle donne in un'impresa).
Metodo di campionamento a grappolo. Le unità di selezione non sono i singoli intervistati, ma i gruppi con successiva ricerca continua al loro interno. Questo campione sarà rappresentativo se la composizione dei gruppi è simile (ad esempio, un gruppo di studenti per ogni flusso di un dipartimento universitario).
Metodo dell'array principale– sondaggio condotto sul 60–70% della popolazione generale.
Metodo del campionamento per quote. Il metodo più complesso, che richiede la determinazione di almeno quattro caratteristiche in base alle quali vengono selezionati gli intervistati. Solitamente utilizzato con una popolazione numerosa.
http://www.hi-edu.ru/e-books/xbook096/01/index.html?part-011.htm– sito molto utile!
Il metodo di ricerca campionario è il principale metodo statistico. Ciò è naturale, poiché il volume degli oggetti studiati è solitamente infinito (e anche se è finito, è molto difficile ordinare tutti gli oggetti; bisogna accontentarsi solo di una parte di essi, una selezione).
Popolazioni generali e campione
La popolazione generale è la totalità di tutti gli elementi studiati in un dato esperimento.
Una popolazione campione (o campione) è una raccolta finita di oggetti selezionati casualmente da una popolazione.
Il volume di una popolazione (campione o generale) è il numero di oggetti in questa popolazione.
Esempio di popolazioni generali e campione
Diciamo che stiamo studiando la predisposizione psicologica di una persona a dividere un dato segmento in relazione alla sezione aurea. Poiché l'origine del concetto stesso di sezione aurea è dettata dall'antropometria del corpo umano, è chiaro che in questo caso la popolazione generale è qualsiasi creatura di origine antropica che abbia raggiunto la maturità fisica e acquisito le proporzioni finali, cioè l'intero parte adulta dell'umanità. Il volume di questa collezione è praticamente infinito.
Se questa predisposizione viene studiata esclusivamente nell'ambiente artistico, allora la popolazione generale sono persone direttamente legate al design: artisti, architetti, designer. Ci sono anche molte di queste persone e possiamo supporre che anche in questo caso il volume della popolazione generale sia infinito.
In entrambi i casi, per la ricerca siamo costretti a limitarci a dimensioni ragionevoli del campione, scegliendo come rappresentanti dell'una o dell'altra popolazione studenti di specialità tecniche (come persone lontane dal mondo artistico) o studenti di design (come persone direttamente legate al mondo dell'arte). immagini artistiche del mondo).
Rappresentatività
Il problema principale del metodo di campionamento è la questione di quanto accuratamente gli oggetti selezionati dalla popolazione generale per la ricerca rappresentino le caratteristiche studiate della popolazione generale, cioè la questione della rappresentatività del campione.
Pertanto, un campione è detto rappresentativo se rappresenta in modo sufficientemente accurato le relazioni quantitative della popolazione generale.
Naturalmente è difficile dire cosa si nasconda esattamente dietro questa vaga formulazione abbastanza accurato. Le questioni relative alla rappresentatività sono generalmente le più controverse in qualsiasi studio sperimentale. Ci sono molti esempi, ormai diventati classici, in cui l'insufficiente rappresentatività del campione ha portato gli sperimentatori a risultati assurdi.
Di norma, i problemi di rappresentatività vengono risolti attraverso la valutazione di esperti, quando la comunità scientifica accetta il punto di vista di un gruppo di esperti autorevoli riguardo alla correttezza dello studio.
Esempio di rappresentatività
Torniamo all'esempio della divisione di un segmento. Le questioni relative alla rappresentatività dei campioni sono qui alla base dello studio: non dovremmo in nessun caso mescolare gruppi di soggetti in base alla loro appartenenza all'ambiente artistico.
Distribuzione statistica della caratteristica osservata
Frequenza del valore osservato
Supponiamo che, come risultato del test in un campione di volume, l'attributo osservato assuma i valori ,, ..., e il valore sia stato osservato una volta, il valore sia stato osservato una volta, ecc., il valore sia stato osservato una volta. Quindi la frequenza del valore osservato è chiamata numero, i valori sono numeri, ecc.
Frequenza relativa del valore osservato
La frequenza relativa di un valore osservato è il rapporto tra la frequenza e la dimensione del campione:
È chiaro che la somma delle frequenze della caratteristica osservata dovrebbe fornire la dimensione del campione
e la somma delle frequenze relative dovrebbe dare l'unità:
Queste considerazioni possono essere utilizzate per il controllo durante la compilazione di tabelle statistiche. Se le uguaglianze non vengono soddisfatte, è stato commesso un errore durante la registrazione dei risultati dell'esperimento.
Distribuzione statistica del valore osservato
La distribuzione statistica di una caratteristica osservata è la corrispondenza tra i valori osservati della caratteristica e le frequenze corrispondenti (o frequenze relative).
Di norma, la distribuzione statistica è scritta sotto forma di una tabella a due righe, in cui i valori osservati della caratteristica sono indicati nella prima riga e le frequenze corrispondenti (o frequenze relative) sono indicate nella seconda linea:



